Winter holidays, starting with Thanksgiving, are the busiest time of the year at Movable Ink. We generate and serve billions of images a day, and ramping up to the holidays we often see our daily traffic double or triple. We need to be able to respond to events as well as anticipate what might go wrong.
In preparation, we hold a pre-mortem: assume that a month from now everything is on fire, how did we get to this point? What can we do to prevent it?
Pre-mortems ideally involve as much of the engineering organization as possible because when we're dealing with unknown unknowns, many different perspectives are helpful. We gather in a room and each engineer gets a set of sticky notes and a marker. On each sticky note, they write down issues that they can imagine might arise, focusing on high probability or high impact. These can range from "a newly-rolled-out service runs out of resources due to insufficient capacity planning" to "Slack is down and we can't coordinate disaster recovery".
After 10 or 15 minutes, we place our stickies on the whiteboard and a volunteer facilitator arranges them by category and we discuss each one. Many times, the discussion leads to new stickies being produced. As we discuss each potential issue, we decide on the severity and determine if and how we might prevent it. In some cases there will be a straightforward prevention, such as adding redundancy or more error handling. In other cases, the issue might be vague or unlikely enough that we don't address it directly but instead decide to add extra logging or alerting. (side note: while dealing with the aftermath of an incident, I almost always look back and wish we had more logging in place) Or we might explicitly decide to accept a risk and take no action, for example: we decide not to run a redundant database cluster for some less-important data because recovering from backups is good enough and we have identified that the cost is not worth it.
One interesting thing we've found is that it's often not enough to solve the immediate problem, we also have to think about the effects of our solutions. Two simplified examples:
- We expect to see a large increase in request throughput, so we have autoscaling horizontally scale out our application servers. As a result, we hit the maximum number of connections on our databases. Action item: scale out database replicas, ensure proper monitoring and alerting for connection limits.
- A caching server for a particular service represents a single point of failure. We add additional caching servers, then notice a decrease in cache hit rate which has downstream effects. Action items: configure application servers to choose cache server priority order based on cache key, ensure monitoring and alerting based on cache hit ratio, scale cache servers vertically where feasible.
After we've created action items, we prioritize them and they go into regular sprint development queues. It's important to start early, as the action items may need to evolve as we implement them.
Neither we nor the development community invented the ideas behind pre-mortems; they're very well-understood in the business and operations world under the umbrella of Risk Assessments. Where our priorities are loosely based around likelihood and impact, something like a Risk Assessment Matrix can help you categorize what you should work on:
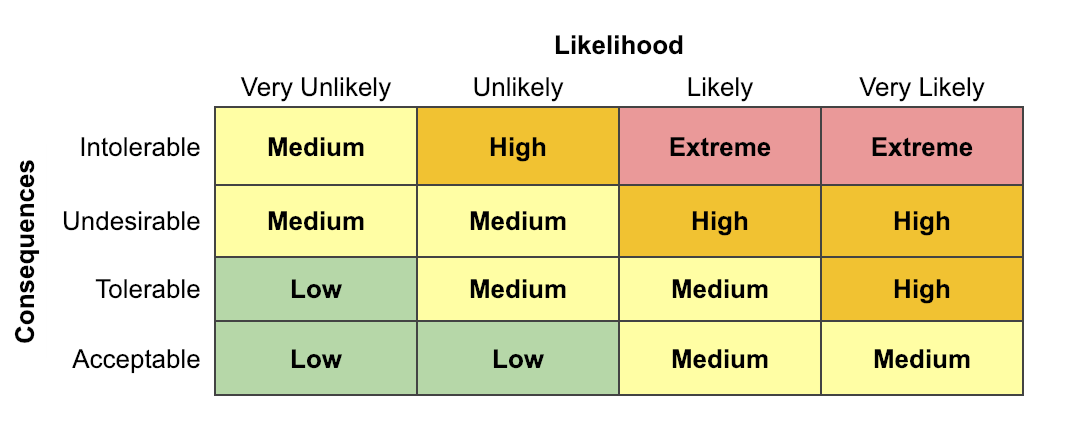
You can use a Risk Assessment Matrix to determine how important the risks are and what you should do about the risks: you can redesign your system to eliminate risks, change your processes and procedures to mitigate them, put in metrics to monitor them, or even accept them. (or any combination of the above) For instance, high-likelihood, low-impact risks may be worth trying to eliminate if you can do so cheaply, whereas moderate-impact but very low-likelihood risks might be accepted and monitored.
The pre-mortem is just one tool we use for keeping things running smoothly; if things do go wrong a post-mortem can illuminate events or failure modes we didn't expect. And our weekly kaizens, meetings where we reflect on what went well and where we can improve, are a useful tool for consistently ratcheting up the quality of our processes and systems.