When we power email content, our customers want to see analytics about how it performed. We process some reports nightly as batch jobs, but other metrics benefit from the ability for customers to see them in real-time. We use counters to store metrics such as total number of email opens, clicks, and conversions, each split by device, location, and a few other metrics. We also segment by time, recording hourly, daily, and total metrics. Any time a user opens an email, we end up incrementing between 20 and 40 counter values. At 30,000 opens per second, we can see many hundreds of thousands of counter increments per second.
While two previous iterations of a system to hold this data used MongoDB and Cassandra, respectively, our current system uses PostgreSQL (a.k.a “Postgres”). We selected Postgres for a couple of reasons: first, we already use Postgres as our primary data store, so we had a good understanding of its production performance characteristics, how its replication works, and what to look for in the event of issues. We also found the SQL interface to be a natural fit with the ORM that our dashboard uses. (Rails’ ActiveRecord)
Storing counters can happen in a couple of different ways. A simple way to implement it is as a read/write operation where you do a read to see the current value of the counter, lock the row, increment it, write the new value, and unlock the row. This has the benefit of requiring a small amount of storage space (a single int) but has the drawback that only one writer can be active at any given time due to the row lock. An alternate approach is to write every increment as its own row and either do periodic rollups or just sum up the values on request. The first approach, despite its limitations, won out for us due to its simplicity and small storage size.
# simplified increment postgres function for incrementing a counter
CREATE FUNCTION oincr(incr_key character varying, incr_value bigint)
RETURNS void AS $$
BEGIN
UPDATE counters
SET value = value + incr_value
WHERE key = incr_key;
IF found THEN
RETURN;
END IF;
INSERT INTO counters(key, value)
VALUES (incr_key, incr_value);
RETURN;
END;
$$ LANGUAGE plpgsql;
While this is approximately how we have implemented counters since Postgres 9.2, Postgres 9.5 has added upsert support which simplifies this. It’s typically more performant and free of race conditions:
# Postgres 9.5+ increment function
CREATE FUNCTION incr(incr_key character varying, incr_value bigint)
RETURNS void as $$
BEGIN
INSERT INTO counters(key, value)
VALUES (incr_key, incr_value)
ON CONFLICT (incr_key) DO UPDATE
SET value = value + incr_value;
END;
$$ LANGUAGE plpgsql;
The single most important thing we did along the way was to decouple our app servers from our counter store and place a queue in between to ensure that we could reconcile our data in the event of Postgres unavailability. We selected nsq, a decentralized queueing system. Initially, our app servers would publish data onto the queue and a worker would pull it off the queue and increment the counter in Postgres. Over time as we served more and more content, we saw that this was unsustainable. Postgres has many great performance characteristics and is getting faster with each release, but there was no way we were going to be able to make hundreds of thousands of reads and writes per second to a single instance.
One of the scaling challenges unique to email is that traffic is very spiky: an email will often go out to hundreds of thousands of people almost simultaneously, which results in a big traffic spike and then dies down. In looking at our data, we realized that at any given time the vast majority of our counter increments were dominated by a couple of recently launched campaigns. We were sending identical messages like “increment the number of iPhone users who opened campaign X between 9am and 10am by 1” thousands of times.
We decided we could take a lot of the load off of Postgres by combining many of these messages together. Rather than incr(x, 1); incr(x, 1); incr(x, 1) we could just do incr(x, 3). We built a worker to sit on the queue between the app servers and the insert worker. It would read individual increments and output aggregate increments. The aggregation worker is a golang app that uses a hashmap to store increment sums for each counter. When the worker receives a message consisting of a counter name and value, it looks for the counter name as a key in the hashmap, and increments the value. Periodically, the aggregates are “flushed”: the hashmap is emptied and its values are sent to the insert worker.
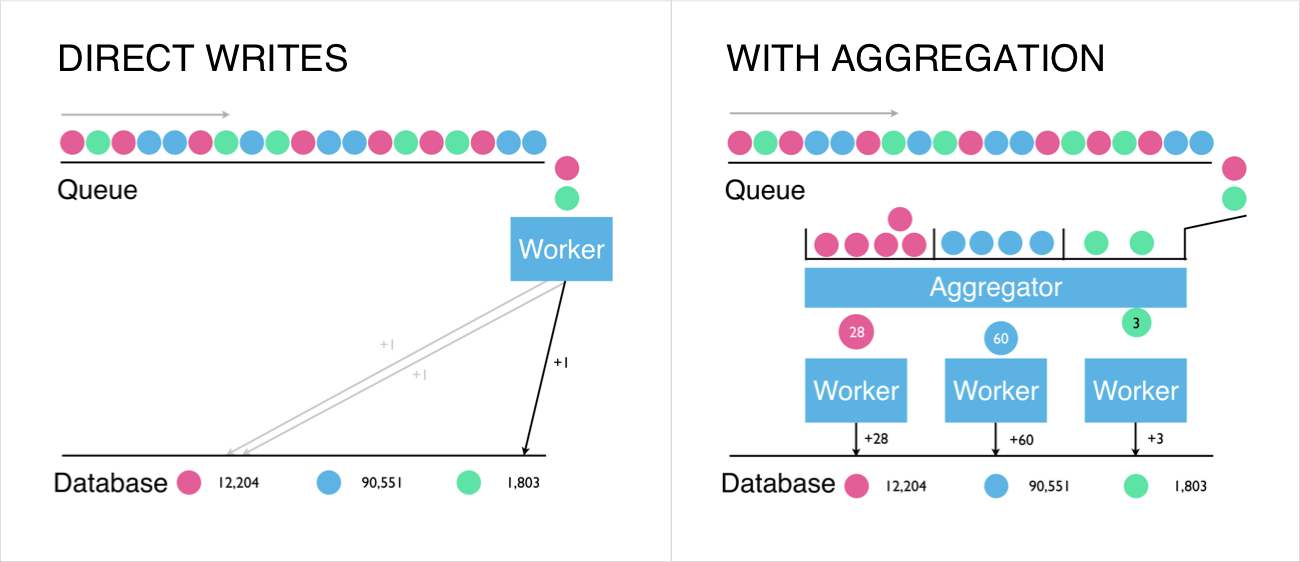
One nice aspect of the aggregate flush interval is that we’re able to use it to tune how many operations go to Postgres: even a modest 1-second aggregate flush interval combines up to 70% of the insert operations while keeping things relatively real-time, but in the event that Postgres can’t keep up we’re able to increase the interval up to a few minutes to further reduce the number of operations.
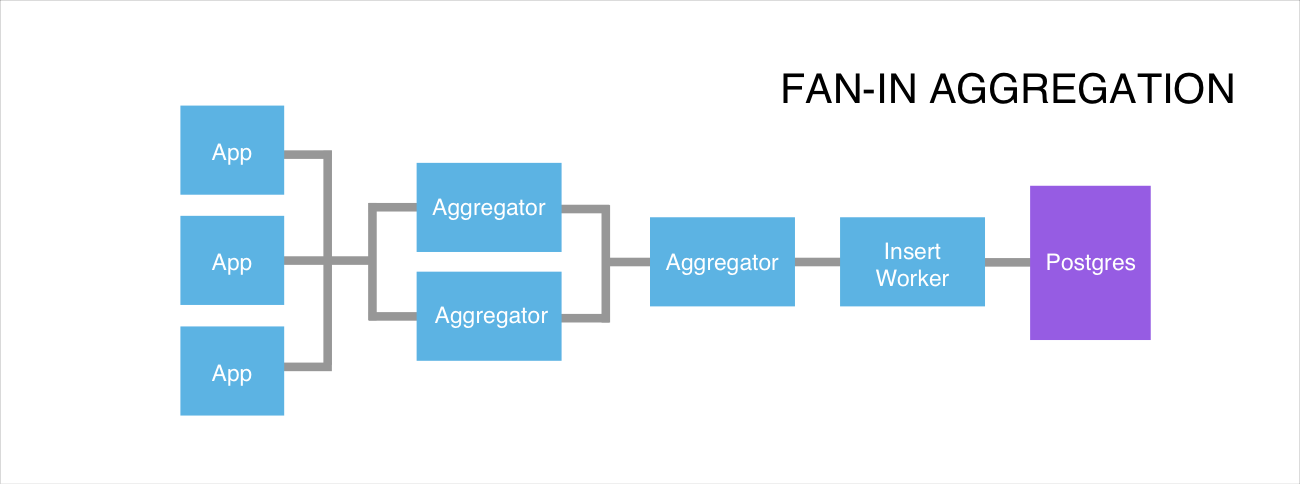
We operate all of this on a single Postgres instance on an EC2 c4.4xlarge, with streaming replication to another instance to use as a hot standby. With tuning, we expect to get to an order of magnitude more request volume before we have to rethink our approach. In the unlikely event that our aggregate workers become a bottleneck, we can continue to add more and use a ‘fan in’ approach: doubling the number of aggregate workers means that more incoming increments can be processed, but also increases the number of aggregate messages emitted so we can add a second tier to aggregate the messages further. The more likely future bottleneck is Postgres, but by aggregating the most common operations we’re spreading the reads and writes out evenly, so we could shard the data across multiple postgres instances.